|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
2025/04/25
【統計学:Topic6】
(Q:クロス集計をして考察しなさい。)
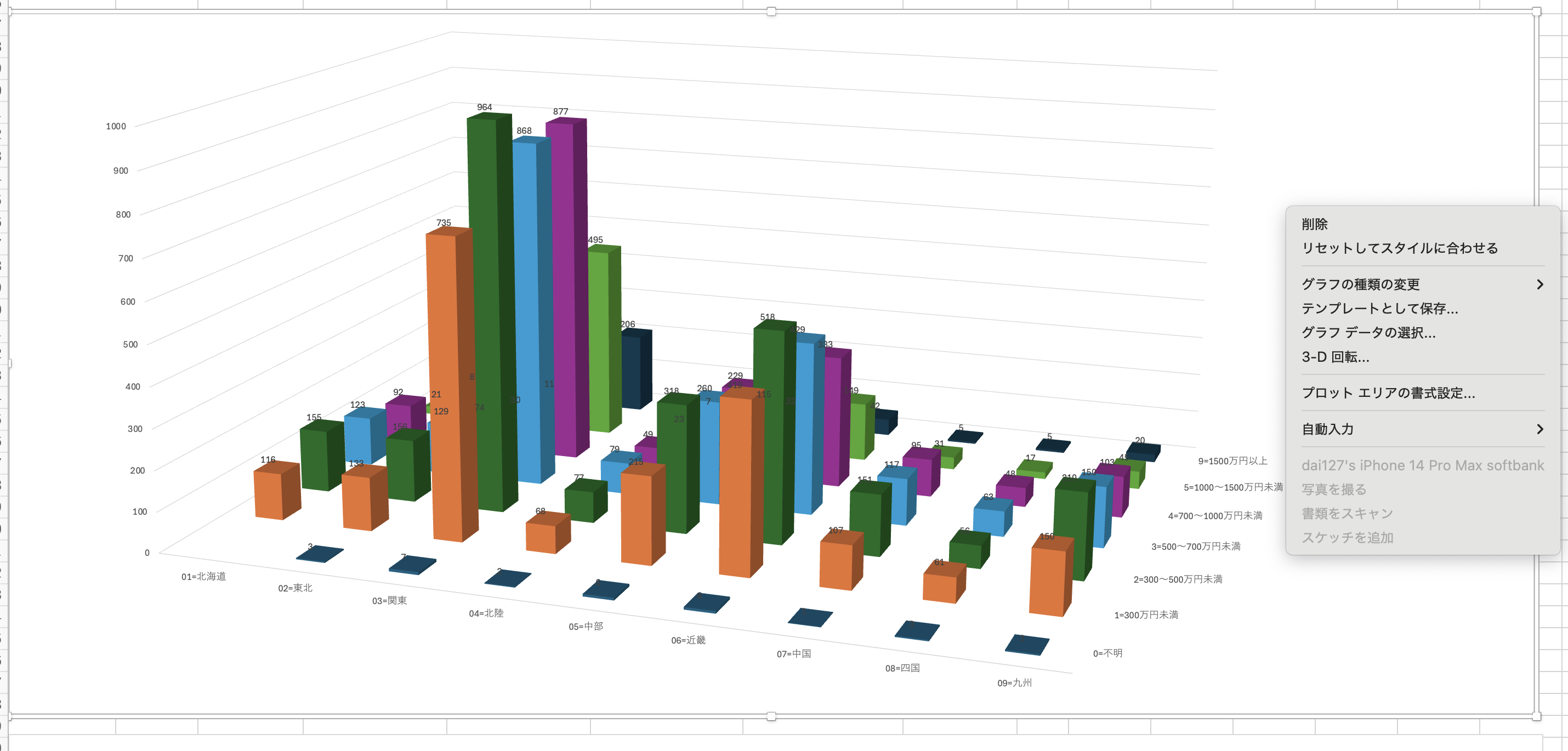
まず、地域別と世帯年収帯のクロス集計を行い、縦棒グラフと100%積み上げ縦棒グラフの両方を作成しました。
すると、関東圏における世帯収入の高さが明確に浮かび上がり、非常に目立つ結果となりました。
この点に興味を持ち、アンケートの本来の目的からは少し離れるかもしれませんが、以下のような追加考察を行いました。
このデータの信頼性を確認するためには、地域別のアンケート参加者数に偏りがないかを調べる必要があると考えました。
そこで単純集計に戻り、地域別の参加者数を確認したところ、関東圏の回答者数が他地域に比べて圧倒的に多いことが判明しました。
このことから、今回の世帯収入に関するデータは「関東の経済的な水準の高さ」をある程度反映しており、一定の信憑性があると判断しました。
そこで、次に政府統計などと比較するために、平均世帯年収を算出しようと考えました。しかし、例えば「4=700~1000万円未満」という階層に対して、分布代表値として「850万円(中央値)」をそのまま使用して良いのか、判断に迷いました。
つきましては先生やLAの皆さまにご相談させていただきたいのですが、このような階級データのみが与えられている場合、平均値を算出する際の最も妥当な方法について、ご指導をいただけますと幸いです。



2025/04/25
【統計学:Topic5】
(Q:最頻値のデータから考察しなさい。)
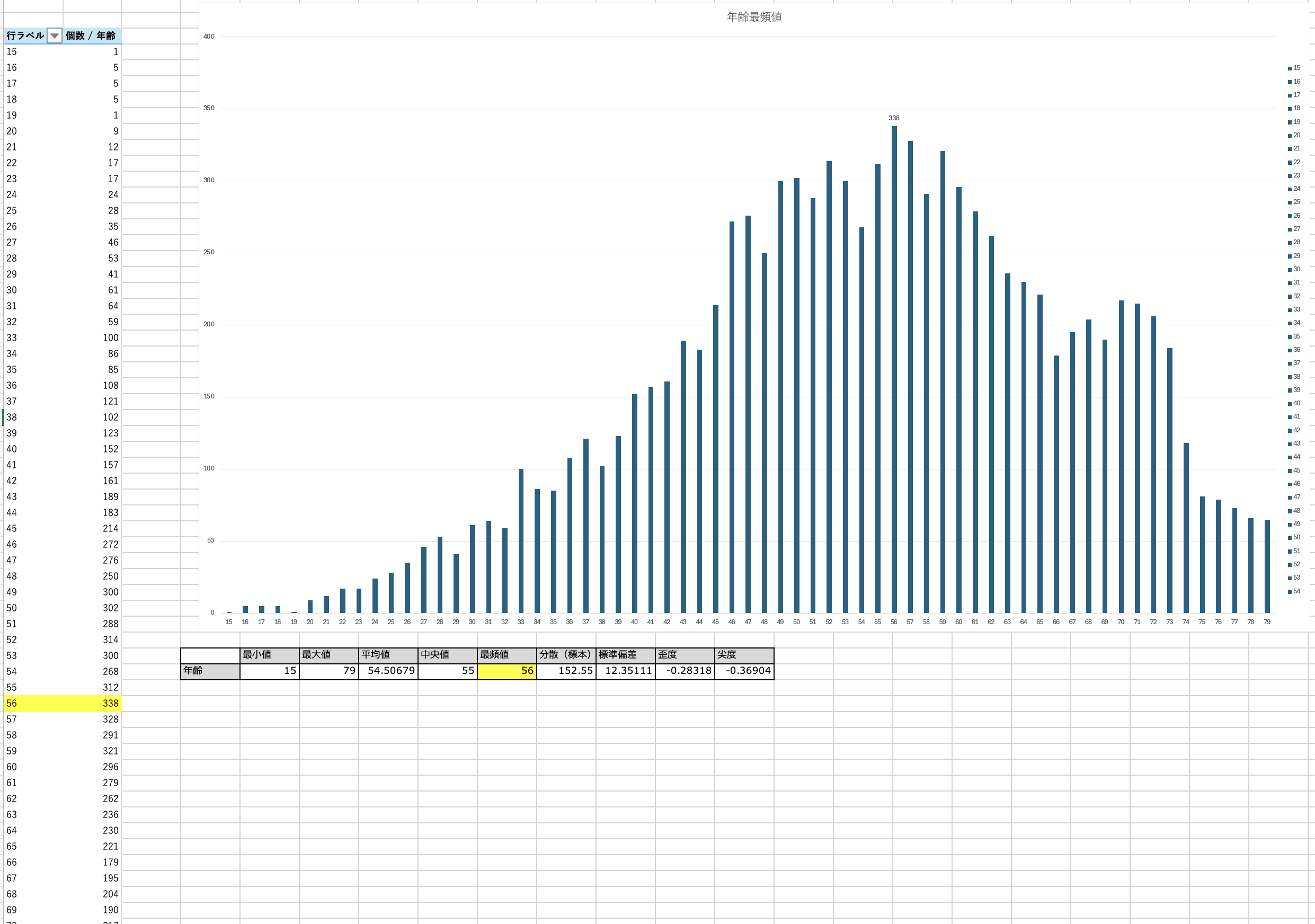
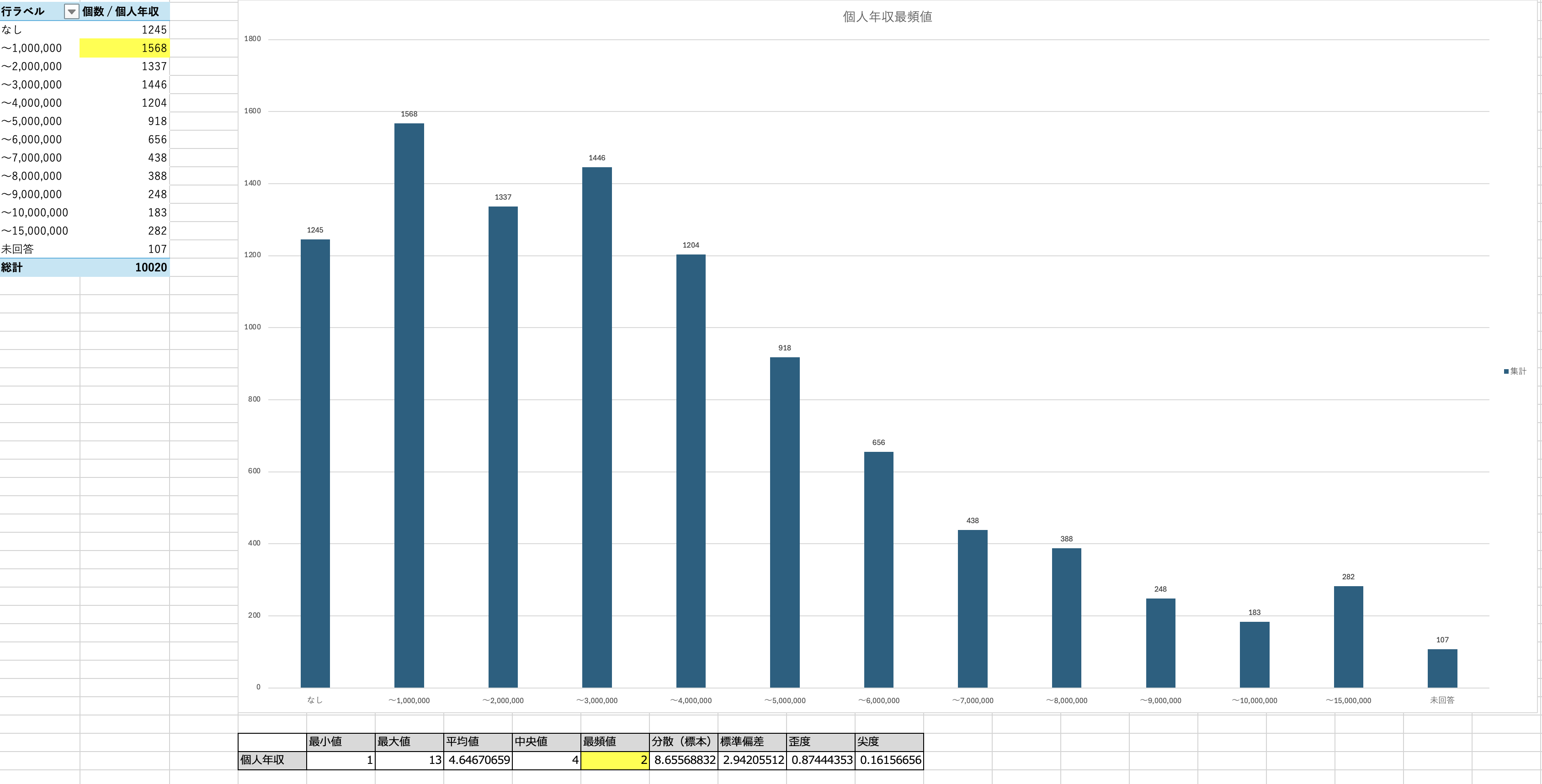
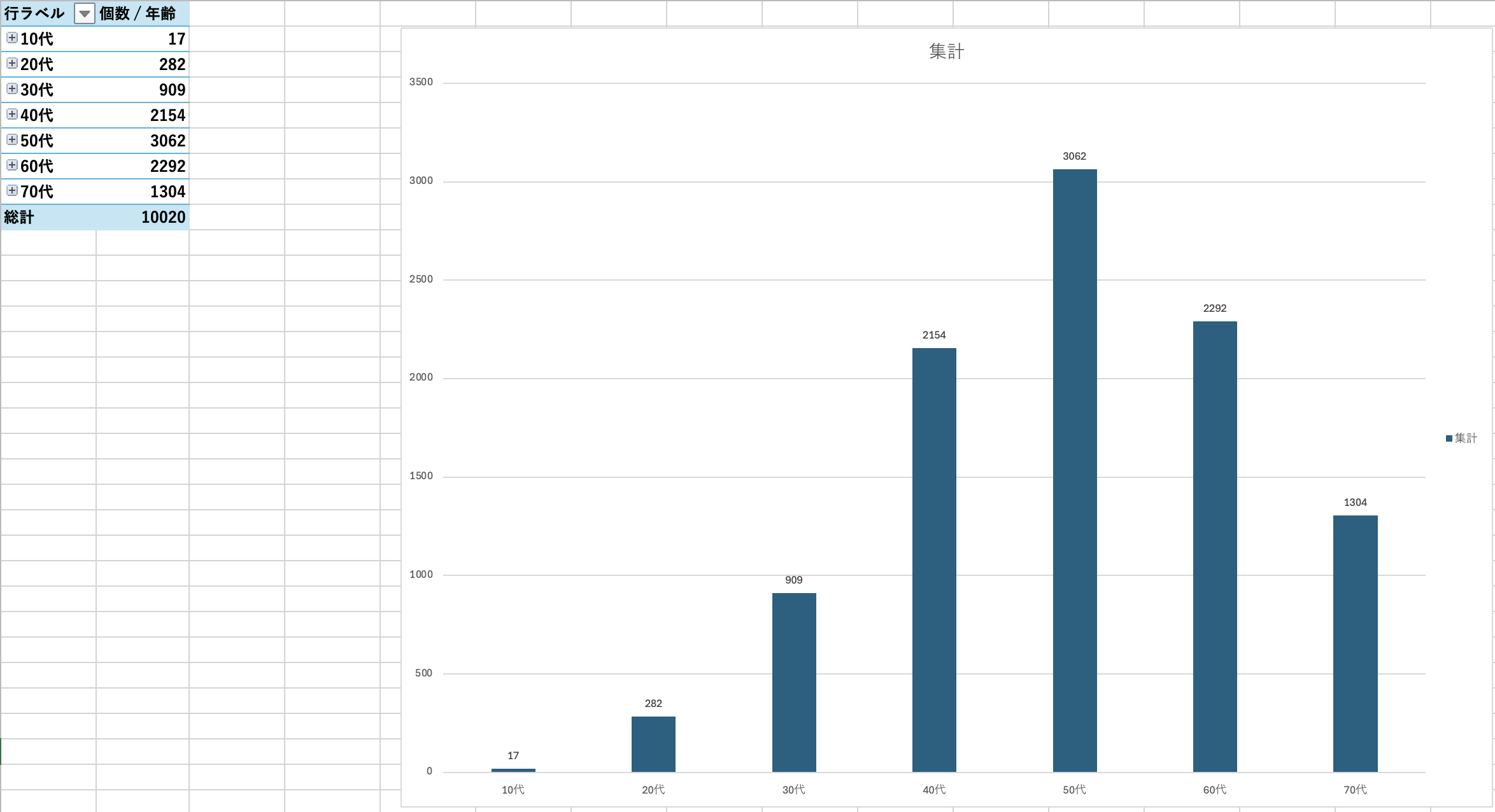
今回、個人年収と年齢に関する最頻値のグラフを作成しました。
結果として、個人年収の最頻値は「〜1,000,000円」、年齢の最頻値は「56歳」でした。
ここでまず、「年齢のわりに年収が低いのでは?」という疑問が湧きました。
その違和感を手がかりに考察を進めたところ、このギャップはおそらく「扶養控除制度」による就業調整、いわゆる「103万円の壁」の影響ではないかと推測しました。
気になってさらに役職に関する最頻値グラフも作成したところ、最頻値は「未記入」、三番目が「その他・該当なし」という結果に。
このことから、非正規雇用やフルタイム以外の働き方をしている層が一定数含まれており、私の仮説もあながち的外れではなかったのではないかと感じています。
アンケートの実施方法など詳細は不明ですが、もしかすると回答者の多くは比較的時間に余裕があり、扶養枠内で働いている方々かもしれません。
そこを加味してデータを捉えることが、企業にとって必須となる可能性を強く感じました。
今回の演習を通じて、自分がまるで数字を追う“刑事”や“探偵”になったような感覚があり、それがとても楽しく、病みつきになりそうです。
また、私は本講義と並行して「生成AI」についても学習しており、両者の関連性の深さにも驚いています。
考えてみれば当然で、生成AIの根幹にあるディープラーニングも、回数を重ねて学習するという意味でまさに「統計学の進化系」なのだと実感しています。
この一年、さまざまな学びを重ねてきましたが、今はそれぞれがつながり始め、統計学・生成AI・社会制度などが一本の線となって見えてくる快感に満ちています。
私がデータ好きであることも相まって、とても充実した学びの時間を過ごせています。
本当にありがとうございます。


2025/04/17
【統計学:Topic4】
(Q:ライブ講義の感想。)
統計学の基礎に関するたくさんのお話を、ライブで直接伺うことができ、とても有意義で楽しい時間となりました。
また、講義中にご紹介いただいた各種の参考サイトも、大変興味深く、今後の学習や実務の中で積極的に活用していきたいと思っています。
これからは自分自身で手を動かし、身の回りのデータを用いてトライ&エラーを繰り返しながら、試行錯誤の中で理解を深めていくつもりです。
学びのきっかけをいただき、本当にありがとうございます。
最後に少し話題に上がった「生成AIの活用法とその信憑性」について、私の考えを共有させてください。
生成AIとは、私の理解では「ネット上に存在する情報の統計的な集合体」であり、私個人の今日の出来事など、ネットに公開していない限り、AIには知る由もないものです。
つまり、AIから出力される情報には、私たちが投稿した情報やネット上にある他者の知見が反映されており、そこに混ざる“虚偽”や“憶測”をどう見極めるかが重要になります。
ファクトチェックの手段としては、書籍やインターネット、あるいは個人的に信用できて、かつ他もそれを認める専門家の発言を直聞きなどがありますが、そのような方の証言を直接聞く機会は限られているため、実際には「本」や「ネット」が主要な情報源となります。
要は誰が書いたか?その信頼性はいかなるものか?
けれどどんなに信頼性が高い人が書いてもその全てが真実であるとは言いきれないと思います。
またその解釈も時代時代により変わっていくものなのでしょう。
その上で、生成AIが提示してくれる情報は「ファクト候補のひとつ」であり、それを鵜呑みにするのではなく、自分自身の手で“裏を取る”ことが求められると感じています。
結局のところ、どれほど優れたツールや技術が登場したとしても、それをどう活かすかは「使う側の人間の力量とアイデアとセンス」にかかっている。
私はそう強く思います。
以下転載
e-Stat:政府統計の総合窓口https://www.e-stat.go.jp/
e-Gov:行政機関のオープンデータ検索サイトhttps://data.e-gov.go.jp/info/ja
SSDSE(教育用標準データセット)https://www.nstac.go.jp/use/literacy/ssdse/
統計グラフコンクール https://www.sinfonica.or.jp/tokei/graph/g70/list_0.html
統計WEB (BellCurve)https://bellcurve.jp/statistics/
なるほど統計学園 https://www.stat.go.jp/naruhodo/

2025/04/17
【統計学:Topic3】
(Q:ピボットテーブルを作成しなさい。)
結局、講義を聞いてから気づけば3時間、、、
ピボットテーブルと遊び倒していました。
最初は講義通り、外れ値のチェックから始めました。
そこまでは予定通り。でも、そこからが本番でした。
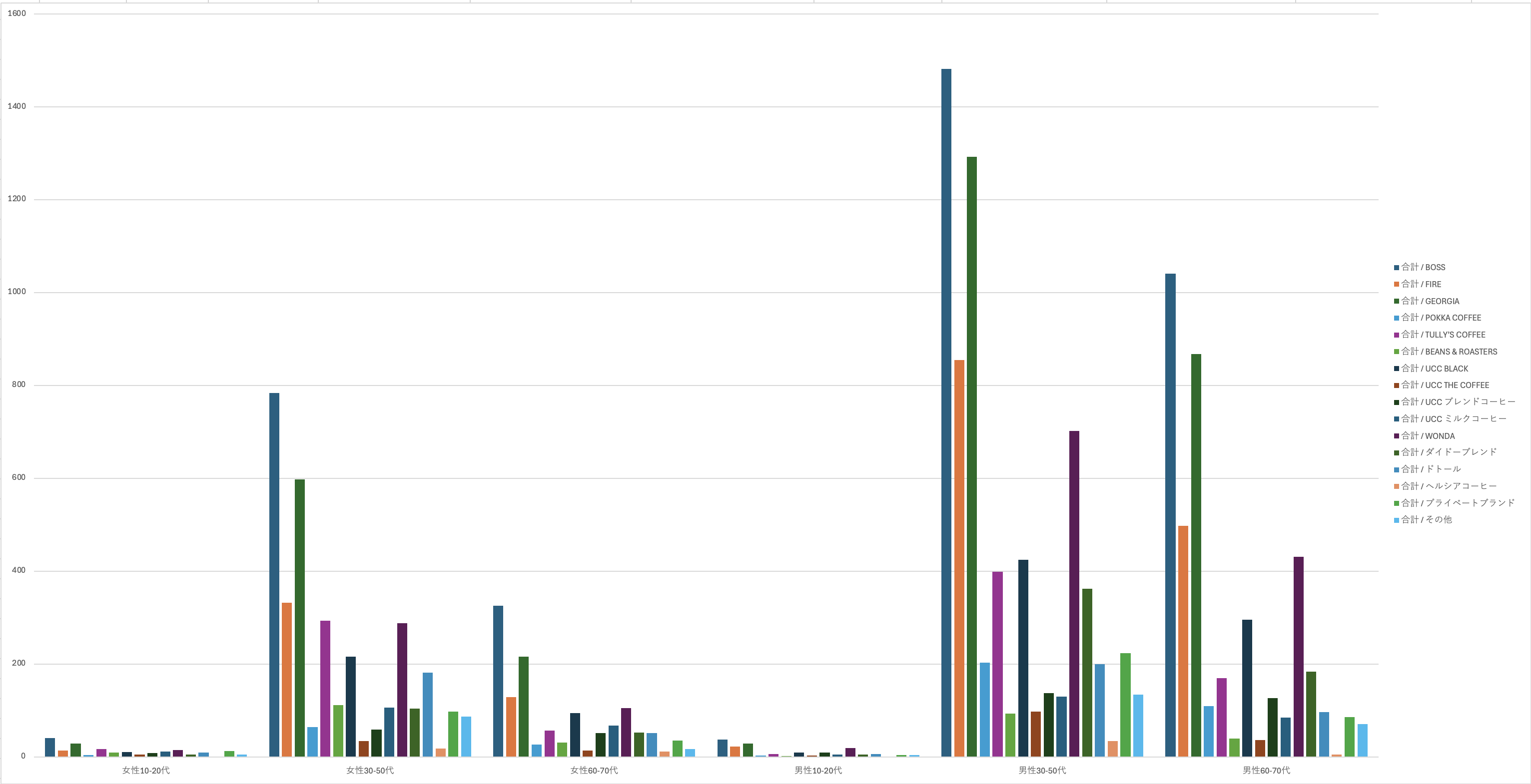
今回は「性年齢別の嗜好品チェック」をテーマに、アンケートQ2をもとにデータを組み立てました。
もし僕がこの調査を設計していたら、きっと“糖度”という指標を加えていたと思います。
缶コーヒーのブランド別に、どれだけ健康志向が見られるか?
横軸を「糖度」にして、年代別の選好を可視化してみたかった。
たとえばUCC BLACK無糖やヘルシアコーヒーは、明らかに“健康”を意識したブランド。
けれど実際に集計してみると、あまり明確な差は見えませんでした。
きっとこれは、ワンダの「ブラック」か「マイルド」か、ジョージアの「微糖」か「カフェオレ」か…?
そういう細かい味の違いが、アンケート上ではひとつのブランド名に吸収されてしまっているから。
※UCCが「BLACK」と「THE COFFEE」をわざわざ分けている理由も、気になってしまいました。
僕はここ3年ほどですが、何でもデータにしてしまう人間です。
ファイナンスや健康データ、趣味活動、コレクション、もちろんビジネス、生産活動…そんなに手間取らずできる考えうる全てのデータを記録しています。
そんな僕が今回の講義を聞いて実際にExcelで作ってみたいと思うピボットテーブルは、たとえば、
・天候と店舗売上の関係+株価変動
・平均気温と体重の変動
・株価変動とコレクション購入の相関
・天候と歩数と体重変化の相関
こうした蓄積データの「点」と「点」が、ピボットを通して“線”になる可能性に、たまらない魅力を感じました。
そして、ふと思いました。
「あぁ、これだったら、生まれてから食べたものも全部つけておけばよかったな」と。
もし生まれてから食べたものをすべて記録していたら、
気温や天候における僕の摂食趣向を調べて自分より自分を知れるきっかけになったかもしれません。
でも、今からでも遅くないですね。
流石に食べるものをデータ化するのは面倒ですが、Googleマップの過去の僕の移動傾向なんかも使えるかもしれません。
それにしてもExcelって本当に面白い。
そしてきっと、Accessならさらにすごいことができる。
いつか本格的に緒戦したいと思います。

2025/04/04
【統計学:Topic2】
(Q:Googleフォームを使用しアンケートを作成。)
今回の講義を受けて早速Googleフォームでアンケートを作ってみました。

2025/04/04
【統計学:Topic1】
(Q:気になる統計データや調査データを調べなさい。)
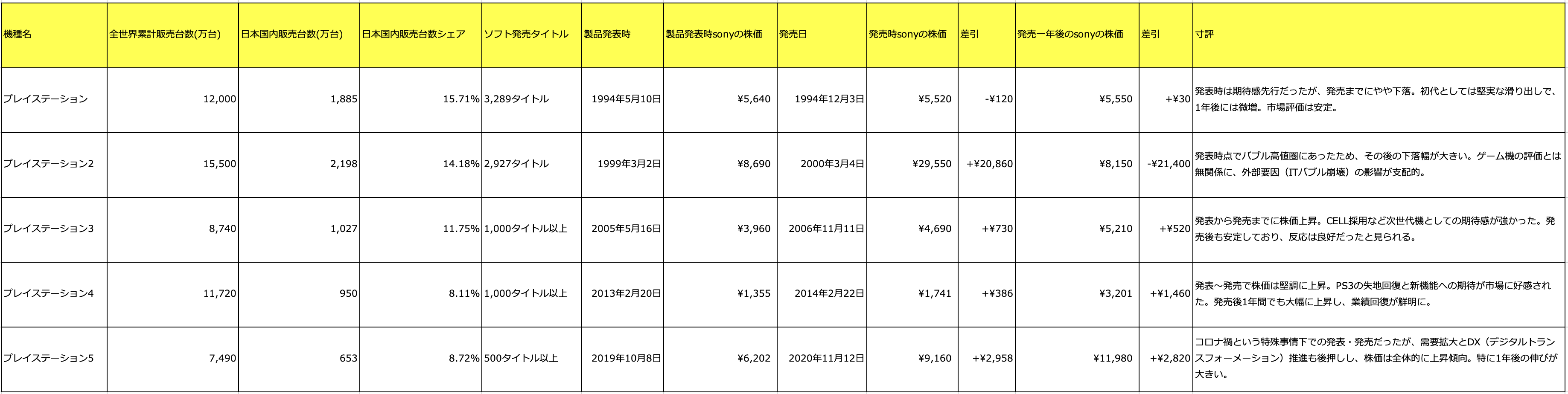
【(1)データ、記事のタイトル】
プレイステ<br>
ーション各機種の販売実績とソニーの株価推移に関する比較分析。
【(2)参照したデータ、記事のURL】
https://ja.wikipedia.org/wiki/家庭用ゲーム機の販売台数一覧
https://kabu.hayauma.net/kabuka/6758/1994.html
【(3)どんなデータ、記事なのか説明文(概要)】
プレイステーション1~5の各モデルについて、全世界・国内の累計販売台数、ソフト本数、製品発表日・発売日とその前後におけるソニーの株価(日本円・米ドルベース)を比較。発表から発売、発売から1年後の株価変動をデータで分析し、ゲーム機のリリースと株価との関連性を探った。
【(4)それがなぜ気になったのか、どんなことが言えそうか】
ゲーム機の成功が企業価値にどう影響を与えるのかに興味があった。
特にPS5のようにコロナ禍でも株価が上昇した例や、PS2時代のITバブル崩壊による下落など、ゲーム産業と市場経済の関連性が読み取れる。
製品単体の評価だけでなく、時代背景の重要性も浮き彫りになった。